Infrastructure
Our infrastructures adhere to all best practices. For example, our AWS infrastructures are built following the AWS Well-Architected Framework, which provides a set of best practices for building a secure, high-performing, resilient, and efficient infrastructure in the Cloud. We also follow standard industry security practices to ensure the security and privacy of our customers' data.
Elastic Infrastructure
Our infrastructure is specially designed to be elastic, meaning it can easily adapt to increasing workloads and traffic. This feature ensures that your application remains performant and responsive at all times. As your application grows and the demands on your infrastructure increase, our system can automatically allocate additional resources to ensure your application stays operational. This approach allows you to focus on creating and improving your product without worrying about infrastructure management.
Backend
One of the key technologies we use to achieve this is Docker, which allows us to easily manage and deploy applications within a containerized environment. Additionally, we use Amazon Web Services' (AWS) Elastic Container Service (ECS) and Kubernetes (GCP and OVH) to provide a highly scalable and reliable infrastructure for your application. By leveraging these powerful tools, we can ensure your application runs smoothly and efficiently regardless of the volume of traffic it receives or how quickly it grows.
We also integrate Redis or Memcached to provide a highly performant distributed caching layer that can help improve the speed and efficiency of your application.
Front-end
For the Frontend, we use AWS CloudFront and S3. This combination offers several advantages. It provides great scalability, meaning it can handle high levels of traffic and automatically adapt. It offers low latency achieved through content caching in multiple locations worldwide, reducing the time users need to access your site. It's cost-effective as CloudFront and S3 are affordable solutions for hosting and serving static content. Lastly, it's secure, with industry-standard security features to ensure data security and privacy. In summary, using CloudFront and S3 for the frontend ensures the speed, reliability, and security of your website.
Base de données
We use Amazon Web Services' (AWS) Relational Database Service (RDS) to provide a highly scalable and reliable database infrastructure for your application. RDS is a managed database service that makes it easy to set up, operate, and scale a relational database in the Cloud. It supports many popular database engines, including MySQL, PostgreSQL, Oracle, and Microsoft SQL Server.
RDS is highly scalable, highly available, and easy to use and manage. It can allocate additional resources to your database as needed, minimize downtime through automated failover procedures, and provide tools to facilitate setup, monitoring, and management. Overall, AWS RDS is a powerful and reliable database service that can ensure the scalability, availability, and performance of your application.
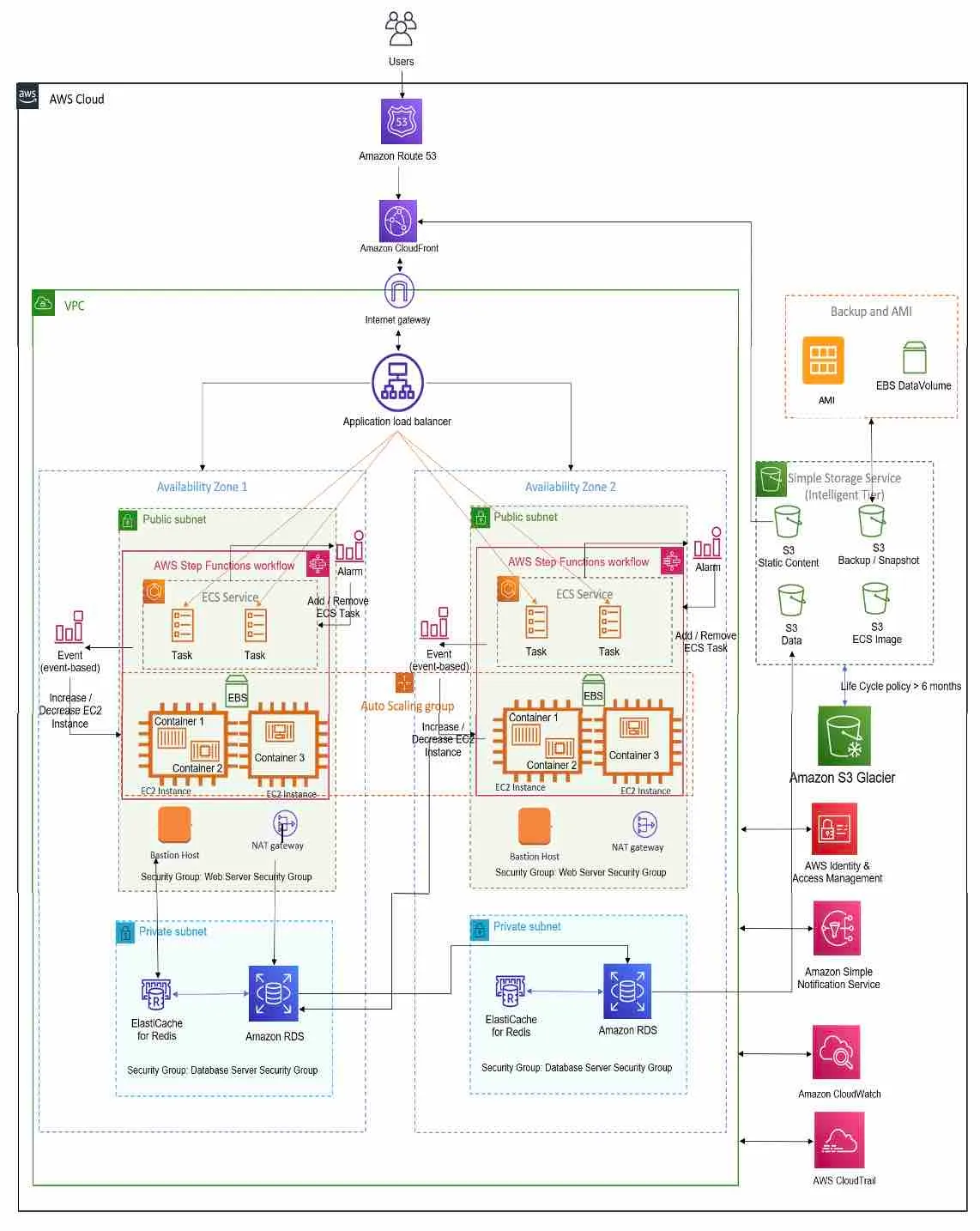
Schema
Architecture diagram of a service on AWS, adhering to AWS best practices.
Redundancy and Recovery
Redundancy and recovery are two essential components of a well-designed infrastructure. Redundancy refers to the practice of duplicating critical components of your system to ensure that in case one component fails, another can seamlessly take over. This approach helps avoid downtime and ensures the availability of your application to users.
In AWS, redundancy can be achieved by using multiple Availability Zones (AZs) and regions. An Availability Zone is a separate data center within a region, and each AZ is isolated from the others to prevent the spread of failures between AZs. By deploying your application across multiple AZs, you can ensure that if one AZ experiences issues, your application can continue to operate from another AZ.
Recovery refers to the implementation of a plan to restore your system in case of failure. This plan should include procedures to identify the cause of the failure, restore data, and resume normal operations. With Webcapsule, recovery can be achieved using automated backups, instant snapshots, and automated failover procedures.
Automated backups are scheduled at regular intervals and can be used to restore data in case of a failure. Instant snapshots are similar to backups but capture an image of your entire system at a specific moment. This can be useful for quickly restoring your system to a known state.
Automated failover procedures are designed to automatically redirect traffic to a backup system in case of a failure. This can be achieved using load balancers and auto-scaling groups. By using these tools, we can ensure that your application remains available even in the event of a failure.
Overall, redundancy and recovery are essential components of a well-designed infrastructure. By implementing these practices, we can ensure that your application remains available and responsive to users, even in the event of a failure.
Other Notable Elements
- Domain name management
- Mail sending capability
- Secret management
An Account You Own
Our system uses a Bring Your Own Cloud (BYOC) model, which means you have full control over your cloud resources and can customize your environment according to your preferences. This ensures that you can choose which applications and services you want to run without being limited by the constraints of a third-party provider. Additionally, this model is often more cost-effective in the long run.
All the resources we deploy are associated with an AWS account that belongs to you. Therefore, you retain full sovereignty over the data and code of the application.
Furthermore, you have the option to leave Webcapsule at any time without losing your work or infrastructure. However, it will be your responsibility to maintain them.
Container orchestration
📄️ AWS ECS (for AWS users)
Container orchestration on AWS
📄️ Kubernetes (for GCP and OVH users)
Container orchestration