R.O.I. d'une bonne usine DevOps

 Cet article est la deuxième partie de notre série sur les coûts du cloud. Elle s’intéresse aux coûts humains de gestion de l’infrastructure web ; la première partie étudie le coût des machines.
Cet article est la deuxième partie de notre série sur les coûts du cloud. Elle s’intéresse aux coûts humains de gestion de l’infrastructure web ; la première partie étudie le coût des machines.
L’infrastructure web, c’est-à-dire l’ensemble des machines qui permettent de faire fonctionner une application web, est un poste de coût qui peut s’avérer important. Il profite cependant d’investissements colossaux réalisés de la part de grands fournisseurs : le prix des machines est en baisse progressive, si bien que le cloud est une technologie accessible. La contrepartie consiste en une complexité croissante des outils qui donnent accès au cloud. Ils demandent des compétences techniques non négligeables et requièrent des temps de mise en place et de gestion importants.
Aussi, il convient d’intégrer le coût humain de la gestion du cloud dans les coûts liés à l’infrastructure web. Ce coût est à considérer selon deux versants : d’une part, le coût brut du temps passé par les équipes techniques ; d’autre part, le gain ou le coût d’opportunité que représente l’usage ou le non-usage des technologies derniers cris.
La vie d’une application web impose de régulièrement mettre à jour son code source, de déployer de nouvelles fonctionnalités ou de corriger des bugs. Cela conduit à opérer sur les machines de production et suppose le respect d’un certain nombre de bonnes pratiques afin de limiter les temps de maintenance et de circonscrire la propagation des erreurs. Les rapports annuels sur le DevOps ont ainsi identifié quatre métriques clés pour évaluer la cohérence de la gestion du cloud. Ces métriques sont :
la fréquence de déploiement le temps de mise en production d’une fonctionnalité le temps moyen pour restaurer un service défaillant la fréquence de bugs liés à la mise en production
 Niveau de performance DevOps — extrait du rapport State of DevOps 2019, rédigé par Google
Niveau de performance DevOps — extrait du rapport State of DevOps 2019, rédigé par Google
Ces métriques se combinent entre elles pour faciliter l’expérience du développeur, mais aussi pour augmenter les performances de l’infrastructure. Selon qu’elles atteignent des bonnes performances plus ou moins élevées sur ces métriques, les entreprises gagneront ou perdront en agilité et en temps de développement. Le retour sur investissement se comprend alors principalement en coût d’opportunité et inclut, selon Google, deux pôles de dépense à considérer : la facilité de gestion des erreurs de mise en production et le temps gagné, les ressources libérées pour les développeurs.
a. bugs en production et coût de redéploiement��
Le processus de mise en production n’est jamais complètement sans risque. On peut avoir oublié un bug, mal formulé un paramètre de configuration et la mise en production engendra alors des erreurs. On rappelle ici que, dans notre application d’exemple (cf article 1), le coût d’une interruption du service est de 268 €/h.
Or la plus ou moins grande agilité dans le processus de déploiement rendra plus ou moins longue la durée de l’incident.
Il s’agit en conséquence d’avoir :
un système de monitoring efficient pour être informé et pouvoir corriger l’erreur au plus vite un système de déploiement rapide pour pouvoir ou bien revenir en arrière ou bien déployer un patch au plus vite. Google a catégorisé, selon les quatre métriques précédemment présentées, différents niveaux dans les pratiques DevOps. Pour simplifier, nous en considérons deux :
le niveau d’excellence, où l’on dispose d’une chaîne de CD efficiente et d’un outil de monitoring performant. Il conduit à ce que l’ensemble des étapes soient automatisées. le niveau medium, où l'on est conscient des bonnes pratiques qu'on n'a pas encore implémentées, soit qu’on les ait remises à plus tard, soit qu’on les trouve coûter cher. La plupart des étapes (tracing, debugging, déploiement) sont encore relativement manuelles.
 Coût des échecs en fonction du niveau d’automatisation
Coût des échecs en fonction du niveau d’automatisation
Il existe un écart de 50% dans les coûts engendrés par les incidents entre les deux niveaux, écart finalement relativement limité. En effet, comme le coût d’un échec de déploiement est beaucoup plus faible dans le scénario où l’on a tout automatisé, cela permet de “risquer” un plus grand nombre de déploiements. Le gain est donc réinvesti en faveur d’une agilité plus grande.
b. bugs en production et coût de redéploiement
Avoir une CI/CD optimisée, des remontées d’erreurs rapides offre une meilleure maîtrise de son application et permet de gagner en agilité. On peut alors tester plus de fonctionnalités, répondre plus rapidement aux attentes des utilisateurs; on a souvent des performances globales meilleures. Ces améliorations sont, cependant, difficiles à apprécier financièrement. On a vu que les équipes étaient prêtes à risquer plus d’incidents lorsqu’elles possédaient une usine DevOps efficiente, laissant supposer qu’elles trouvent le gain apporté par l’agilité supérieur au coût des incidents supplémentaires. On mentionnera aussi que la satisfaction des développeurs augmente : selon le rapport de Google, les développeurs d’une entreprise d’un haut niveau DevOps ont 2.2 fois plus de chance de recommander leur entreprise que les autres.
Il ne nous ait cependant pas possible de réaliser une estimation précise des gains apportés par cette agilité.
Ce qui, maintenant, peut faire l’office d’un chiffrage financier est le temps passé à gérer la chaîne de déploiement.
c. coût de gestion
La gestion humaine du cloud est probablement le poste de dépense le plus important. Les compétences y sont rares et, les technologies évoluant vite, leur maîtrise demande du temps et de la patience.
Cependant, il n’existe pas de constat clair sur le temps nécessaire à la gestion d’une application. On peut en recoupant différentes sources d’informations, l’estimer à 1/5 — 1/10 du coût du développement du projet.
Le rapport Google signale en outre que, dans la plupart des cas, 1 à 2% du DevOps est passé à des tâches inutiles ou inefficaces.
Si l’on admet même cette gestion à seulement une journée de développement par mois, son coût est autour de 800 E/mois. Il s’ensuit qu’en mettant en place une gestion au maximum automatisée, on libère du temps pour les développeurs ; si on délègue la gestion des déploiements à une plateforme centralisée, on réduit le besoin en compétence DevOps, difficile à trouver et coûteuse.
Synthèse des coûts
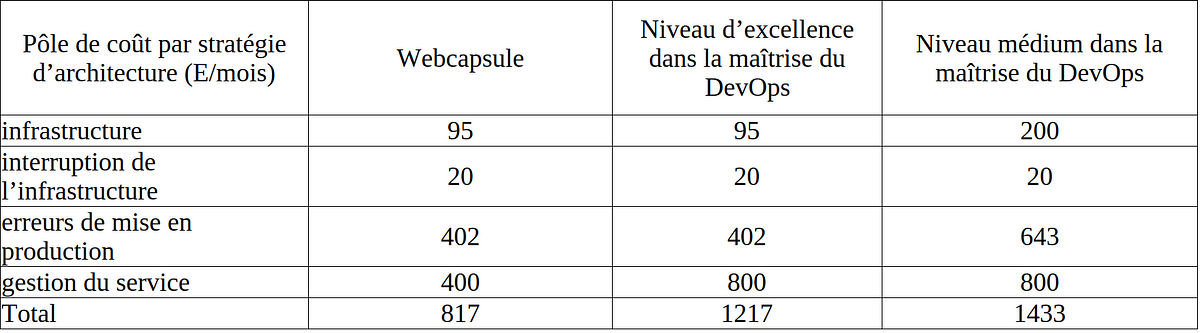 Synthèse des différents pôles de dépense selon la politique DevOps mise en place
Synthèse des différents pôles de dépense selon la politique DevOps mise en place
Le pôle de dépense le plus important dans la gestion du cloud est donc celui du temps humain passé à sa gestion.
Or, comme l’indique le rapport de Puppet, la plupart des entreprises demeurent dans leur gestion du cloud à un niveau intermédiaire. Il existe donc un champ de progression possible. Les bonnes pratiques sont souvent connues, mais leur mise en place demande du temps et des compétences : elles sont régulièrement remises à plus tard.
En outre, nous constatons que le développeur d’une entreprise de bulletin de paie gérera les mêmes problèmes que celui développant une application de gestion des horaires de train.
On peut ainsi considérer les élasticités des différents pôles de coût et constater que la gestion du service est peu élastique : il coûtera à peu près autant de temps à une équipe de gérer 100 000 utilisateurs que d’en gérer 200 000 utilisateurs.
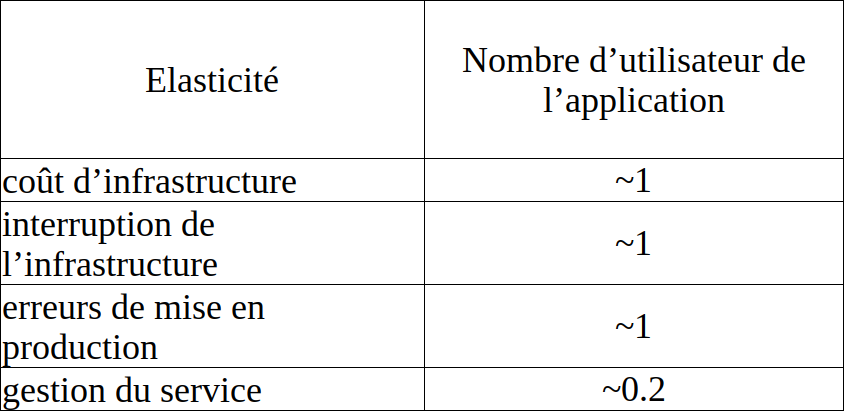 Élasticité des différents pôles de coût
Élasticité des différents pôles de coût
L’ensemble de ces statiques engagent vers une gestion centralisée des déploiements et des infrastructures web. Dans le futur, les plateformes comme webcapsule devraient prendre le pas sur les déploiements en interne.